利用Python从音乐文件中提取专辑封面
使用iTunes管理音乐文件时,我给每张专辑都设置了专辑封面。iTunes把专辑封面图片嵌入到了每一个音频文件中,当我们在资源管理器中以缩略图的形式查看这些文件时,就可以看到每个音频文件显示的都是专辑封面。
在我突发奇想制作“来自封面们的封面”这个可视化效果时,需要从这些音频文件中提取出专辑封面,本文将具体探讨利用Python提取专辑封面的方法。
音乐格式浅析
我的音乐文件主要有MP3文件和M4A文件两种,因此下面我将简要介绍下这两种音频格式,重点为专辑封面是如何嵌入在这两种格式的文件中的。
MP3
MP3文件使用ID3记录歌曲信息。ID3有两个版本,ID3v1在MP3文件的末尾128字节,以TAG开头,记录标题、作者、专辑、出品年代、类型、音轨序号等信息;ID3v2在MP3文件的头部,以ID3开头,由许多“帧”构成,每一帧记录一种属性,可以方便的扩展。下表是ID3v2的结构:
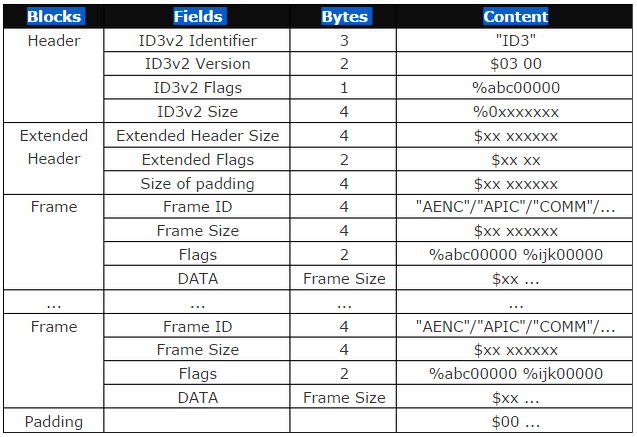
以下是ID3v2各帧的定义:
AENC Audio encryptionAPIC Attached pictureCOMM CommentsCOMR Commercial frameENCR Encryption method registrationEQUA EqualizationETCO Event timing codesGEOB General encapsulated objectGRID Group identification registrationIPLS Involved people listLINK Linked informationMCDI Music CD identifierMLLT MPEG location lookup tableOWNE Ownership framePRIV Private framePCNT Play counterPOPM PopularimeterPOSS Position synchronisation frameRBUF Recommended buffer sizeRVAD Relative volume adjustmentRVRB ReverbSYLT Synchronized lyric/textSYTC Synchronized tempo codesTALB Album/Movie/Show titleTBPM BPM (beats per minute)TCOM ComposerTCON Content typeTCOP Copyright messageTDAT DateTDLY Playlist delayTENC Encoded byTEXT Lyricist/Text writerTFLT File typeTIME TimeTIT1 Content group descriptionTIT2 Title/songname/content descriptionTIT3 Subtitle/Description refinementTKEY Initial keyTLAN Language(s)TLEN LengthTMED Media typeTOAL Original album/movie/show titleTOFN Original filenameTOLY Original lyricist(s)/text writer(s)TOPE Original artist(s)/performer(s)TORY Original release yearTOWN File owner/licenseeTPE1 Lead performer(s)/Soloist(s)TPE2 Band/orchestra/accompanimentTPE3 Conductor/performer refinementTPE4 Interpreted, remixed, or otherwise modified byTPOS Part of a setTPUB PublisherTRCK Track number/Position in setTRDA Recording datesTRSN Internet radio station nameTRSO Internet radio station ownerTSIZ SizeTSRC ISRC (international standard recording code)TSSE Software/Hardware and settings used for encodingTYER YearTXXX User defined text information frameUFID Unique file identifierUSER Terms of useUSLT Unsychronized lyric/text transcriptionWCOM Commercial informationWCOP Copyright/Legal informationWOAF Official audio file webpageWOAR Official artist/performer webpageWOAS Official audio source webpageWORS Official internet radio station homepageWPAY PaymentWPUB Publishers official webpageWXXX User defined URL link frame
对于专辑封面,我们需要读取的是APIC。
M4A
M4A文件也使用了一种类似于ID3的方式按帧存储音频文件的信息,称作ATOM。关于M4A格式的详细说明文档可以到这里下载查看,我就不再赘述了。
在M4A格式的文件中,专辑封面的标志字为covr。
图片格式浅析
内嵌在音频文件中的图片通常为JPG或PNG格式的,为了将它们提取出来,我们需要对这两种图片的格式也有所了解。
JPG
JPG文件采用JPEG File Interchange Format(JFIF)标准,由一系列标记或标记块组成。每个标记有两字节,第一个字节固定为FF,第二个字节表示标记的类型,不为00或FF。JPG文件的开始标记和结束标记分别为FF D8和FF D9。整个文件的结构见下表:
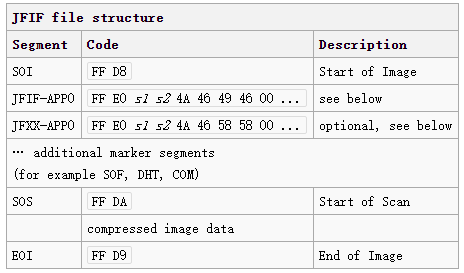
对于提取专辑封面,我们只需要知道开始标记和结束标记即可,其他标记的说明可点击本节开头的链接参考维基百科。
PNG
PNG(Portable Network Graphics)文件也由若干数据块组成。

除文件头外,其他数据块格式如下:
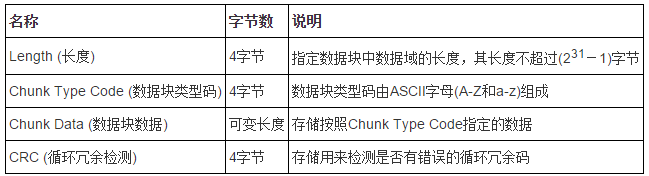
其文件头为89 50 4E 47 0D 0A 1A 0A,图像结束数据块在没有人为加入数据的情况下通常为00 00 00 00 49 45 4E 44 AE 42 60 82。
如需了解PNG格式的其他详细信息,可以查看它的官方说明文档。
利用Python提取专辑封面
了解了上述信息,就可以开始利用Python编写程序提取音频文件中的专辑封面了。
为了对比字节,找到图片,我们需要使用二进制格式读取(rb)音频文件。
我最初的想法是利用正则表达式匹配图片的文件头及文件尾来找到对应的图片,但是在操作中对于较长的字符串利用正则表达式 b'covr.+?(\xFF\xD8.+?\xFF\xD9)'无法匹配成功,而使用表达式b'covr.+?\xFF\xD8.+?'进行匹配,会发现匹配到的结果\xFF\xD8后面仅有一小部分数据,因此我怀疑Python的正则表达式对字符串的长度有限制。
所以最终我使用了bytes类型的find方法来寻找标志信息在字符串中的位置,通过对整个字符串不断的裁剪,最终获取图片信息。
整个函数的编写我认为用户是知道音频文件的类型的,因此音频文件的格式作为一个输入参数。而音频中内嵌的图片格式我们通常是不知道的,需要程序自行判断。虽然实际中大部分为JPG格式的图片,但是我们默认图片为PNG格式的,因为JPG格式的文件头只有两字节,在音频文件的非图片位置出现的可能性非常高,容易发生误判(即如果文件是PNG格式的,也很有可能在APIC或covr后方找到JPG文件的文件头标志),而PNG格式的文件头有八个字节,发生误判的概率微乎其微。
在实际操作中我还发现,MP3文件中即使APIC帧头没有出现,也是可以正常保存专辑图片的,因此我实际匹配的不是APIC而是ID3。因为一旦ID3没有出现,就说明该文件不存在ID3v2信息。
最后,部分由Photoshop生成的JPG图片,在实际的开始标记前添加了一个伪开始标记,用来增加它自己的一些信息,导致图片不能被其他图片浏览器正常打开。因为图片中除了开始部分,不会再出现FF D8,因此需要检查一下,裁剪掉冗余信息。
以下就是提取专辑图片函数的完整代码:
def readAPIC(filename, artist, album, filetype):
fp = open(filename, 'rb')
if filetype == '.m4a':
covr = b'covr'
elif filetype == '.mp3':
covr = b'ID3'
else:
return False
imagetype = '.png'
start = b'\x89\x50\x4E\x47\x0D\x0A\x1A\x0A' # 默认为png,因为png的文件头长,误匹配到的概率低
end = b'\x00\x00\x00\x00\x49\x45\x4E\x44\xAE\x42\x60\x82'
a = fp.read()
covr_num = a.find(covr)
a = a[covr_num: -1]
start_num = a.find(start)
end_num = a.find(end)
if start_num == -1: # 不为png则为jpg
start = b'\xFF\xD8'
end = b'\xFF\xD9'
start_num = a.find(start)
end_num = a.find(end)
imagetype = '.jpg'
if imagetype == '.jpg':
pic = a[start_num: end_num + 2]
while pic[2: -1].find(start) != -1:
pic = pic[pic[2: -1].find(start) + 2:-1]
elif imagetype == '.png':
pic = a[start_num: end_num + 12]
while pic[8: -1].find(start) != -1:
pic = pic[pic[8: -1].find(start) + 8:-1]
fo = open('images/' + artist + '-' + album + imagetype, 'wb')
fo.write(pic)
fp.close()
fo.close()
return True